
A Primer on Machine Learning in Healthcare
How to use ML to diagnose diseases faster


Source: XKCD
There’s a lot of talk about how machine learning (ML) is revolutionizing healthcare — how ML is doing everything from diagnosing diseases to discovering to new treatments.
But have you wondered what that actually means? What does it mean for ML to diagnose a disease and when is it actually used in the real world? How will the healthcare industry change because of this new technology? I’ve worked in the cloud, ML, and healthcare space at Microsoft, Stanford, and PathAI and I’ve learned a thing or two about the answers to these questions.
In this series, I’ll be sharing some of the insights that I have gleaned by giving a conceptual overview of important machine learning algorithms and explaining how they are used in healthcare settings. Specifically, in this post, I will:
Review the basics of machine learning
Discuss the different learning styles of machine learning algorithms
Explore how some of the most popularly used algorithms in healthcare — regression algorithms — work
Recommend some open-source datasets
Suggest some exciting job opportunities!
What is Machine Learning?
Arthur Samuel, a pioneer of artificial intelligence research, described machine learning as a subset of artificial intelligence which gives “computers the ability to learn without being explicitly programmed.” Essentially, machine learning allows computers to learn from examples rather than through rules.
It’s similar to how you would teach a child how to recognize a dog — rather than trying to give them explicit rules of what a dog is like (e.g. a dog’s ear is 5 inches long), you would show them examples of what different types of dogs and help them build their own mental model of what a dog looks like. After this mental model is created, every time the child sees an animal, they will run the image of the animal through their mental model to determine whether the animal is a dog or not.
Similarly, you generate a machine learning model by training a machine learning algorithm with data. The algorithm is the actual procedures written in code while the model is the output of the algorithm run on data. After training, this machine learning model can take in any new input and return to you some output.

Source: Kayk Waalk
Machine Learning Approaches
Algorithms used in machine learning broadly follow into three categories: supervised, unsupervised, and reinforcement learning. Each approach differs in the types of inputs it takes and what feedback it provides to itself.

Source: IBM
Supervised Learning
Supervised learning is like learning with a teacher. The teacher knows the correct answers so they can correct you when you make a mistake. Through several iterations of your teacher correcting you, you can arrive at a good mental model for a particular concept.
Similarly, in machine learning, we provide the algorithm with a labeled dataset, which includes both the inputs and the desired outputs (or labels). The algorithm compares the output of its model on some data to the correct answer provided as part of the dataset. For every wrong answer, the algorithm tweaks the model until the error rate on the model is sufficiently low. Then, given any new example, the model will spit out an answer based on the function that it learned during the training phase.
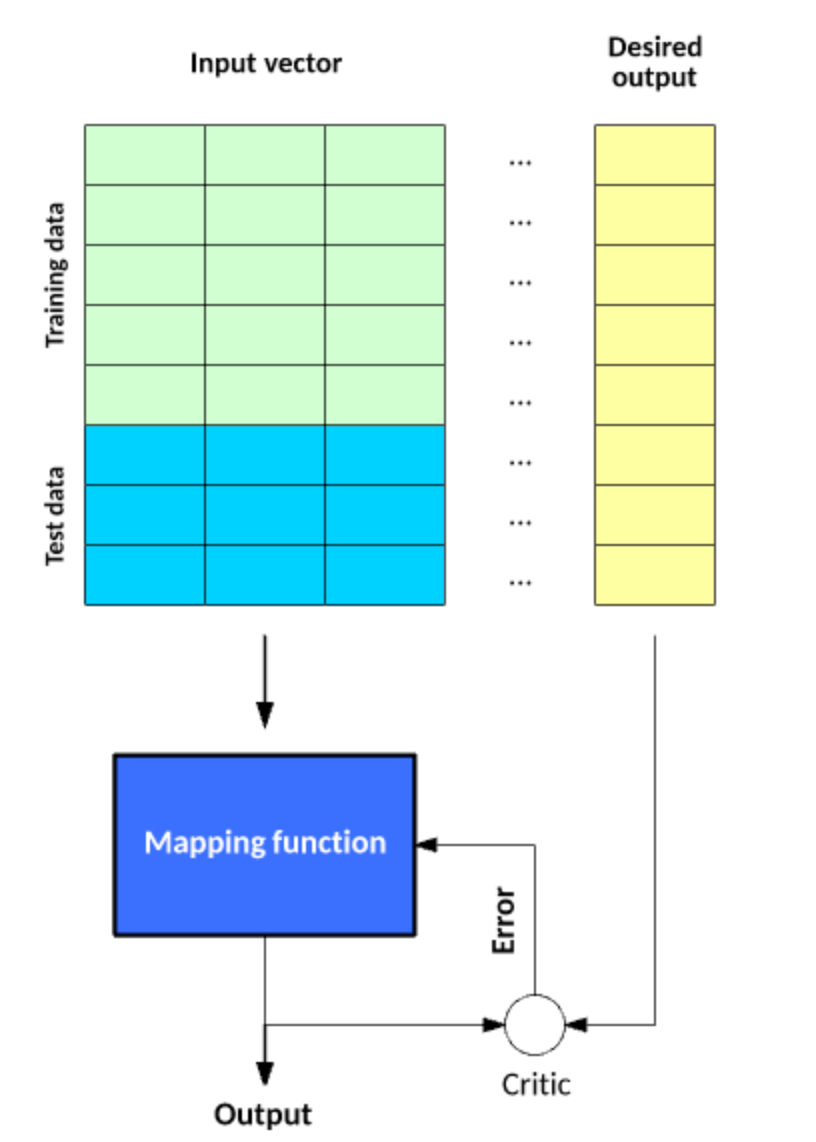
Source: IBM
Supervised learning is often used for:
Categorization: Classify data into categories (e.g. classify whether a patient has a disease or doesn’t)
Regression: Predict a value (e.g. predict house price)

Source: XKCD
Unsupervised Learning
Unsupervised learning, on the other hand, is like learning without a teacher. You get no feedback so you have to see if you can detect interesting patterns in the data all by yourself.
Similarly, in machine learning, we provide the algorithm with an unlabeled dataset, which includes inputs but no desired outputs (or labels). Since there is no way to supervise the function, the algorithm attempts to segment the dataset into similar classes instead.

Source: IBM
Unsupervised learning is often used for:
Clustering: Discover inherent groupings in the data (e.g. group customers by their purchasing behavior) (NOTE: in categorization, each group has a predetermined label whereas in clustering those labels are missing)
Association: Probability of the co-occurence of items in a collection (e.g. find the probability that a person will watch show X given that they watched show Y)
Dimensionality reduction: Reduce variables of a dataset for finding commonalities (e.g. find questions in an exam that test the same skill and take all but one of them out)
Reinforcement Learning
With reinforcement learning, you have a teacher except they teach you through trial and error instead of telling you what the correct answer is. It’s similar to how you might train a dog to learn new tricks.
Since reinforcement learning is a bit more involved, let’s look at a quick example. Let’s say that you are learning how to play chess. You, of course, win chess by checkmating your opponent’s king. The first time you play chess, you have no idea what moves would help you win. But, after playing tons of games, you start learning which moves increase your chances of winning and which ones don’t. You start building up a mental model of the chessboard states in your head — checkmating your opponent is best, placing the opponent in check is good, etc. You can score each state based on how it impacts your probability of winning. With this mental model of which states are good to be in vs. which ones aren’t, you can optimize how to win the game.
Similarly, in reinforcement learning, the algorithm explores the state-action pairs within an environment and learns how good being in that state is for getting the ultimate reward. Then, in practice, the model uses this information to figure out what the best action is for any given state.

Source: IBM
Reinforcement learning is used often to help teach programs to play games (e.g. the famous AlphaGo program that beat a Go world champion) and help robots navigate.
The program learns to play games by playing against itself thousands of times. It builds up a state-action table for itself by figuring out through trial-and-error which actions from which states help it win the game the fastest. Then, when the program is playing in an actual competition, the program can just look up the best move to take in its states-actions table.
Teaching a robot to navigate works similarly — the robot’s program explores an environment and builds up a state-action table for itself by figuring out through trial-and-error which actions from which states help it get the highest reward. Then, when the robot’s program is navigating in the real world, the program can just look up the best move in its states-actions table.
Regression Algorithms
Regression algorithms are one of the most commonly used types of algorithms in the healthcare space. They fall into the supervised learning category.
Algorithm Details
Regression algorithms estimate a mapping function between some inputs and an outcome. Different regression algorithms are used to predict different types of values. For example, logistic regression is used to predict discrete values (e.g. a person has cancer or not) while linear regression is used to predict continuous values (e.g. a person’s blood glucose level).
To understand how regression algorithms work, let’s look at a simple example. Let’s say that you wanted to predict well a student performed on a test based on how many hours they studied. You would:
Train a linear regression algorithm by giving it data on how previous students performed on a test and how many hours they studied
Guess values for m and b in a linear function (function of the form y = mx + b, where x = number of hours studied and y = score on the test). The goal is to fit a line that is nearest to as many data points as possible.
Calculate how well this linear function performs on your training data
If the error rate is too high, update the values for m and b
Repeat steps 3 & 4 until the error rate is low
Once your model is trained, you can give it information on how many hours any new student studied and it will tell you the student’s predicted score! Logistic regression works similarly except the algorithm would guess coefficients for a logistic function instead of a linear function and your output would be the probability of a discrete event happening (e.g. 95% a person has cancer) instead of continuous (e.g. a person’s predicted blood pressure levels).

Source: Towards Data Science
Regression Algorithms in Healthcare
Logistic regression is used often in healthcare for risk stratification, identifying which patients need help right away and which don’t. Some commonly asked questions are: is this patient at risk for diabetes? Does this patient need to be admitted to the ICU? What is the patient’s likelihood of being readmitted into the hospital?
Traditionally, risk stratification was based on simple scores using human-entered data. Surveys were given to patients in their doctor’s offices or found online and the scores were calculated by hand. However, it was not feasible to regularly screen millions of individuals or adapt models to missing data, making manual risk stratification extremely difficult.

Source: MIT
Now, we can take advantage of the massive amount of data stored in electronic health record (EHR) systems in hospitals — data with information about a patient’s demographics, service place, health insurance coverage, medications taken, laboratory indicators, speciality of doctors seen, procedures performed, and diagnosis codes — and train logistic regression models to do risk stratification automatically. This, in turn, can help us catch problems very early on!

Source: MIT
Challenges
Regression algorithms are very promising but there are a lot of unique challenges in using these algorithms for the healthcare sector. Some of the key challenges are:
Observational Data
EHRs are observational databases since they record when an action was taken (e.g. a disease was detected, a lab test was ordered) instead of when the health event actually started (e.g. when the disease actually started). This makes EHRs an indirect measure of a patient’s true state. If this isn’t taken into account when building machine learning models, the model can learn the wrong lesson!
For example, let’s say that our data shows that patients tested at 4 AM with normal lab results had a lower survival rate than patients tested at 4 PM with abnormal lab results. Does that mean that normal lab results correlate with lower chances of surviving? Of course not! It’s because doctors will usually only order a lab test for a sick patient at 4 AM. But, if you don’t account for these healthcare processes (e.g. lab tests are not usually ordered at 4 AM), you might end up interpreting the data incorrectly.
Right and Left Censored Data
Since patients change health insurance companies often but their data doesn’t follow them, health data is often right or left censored. The data is left censored when you know the patient’s outcome (e.g. had cancer or not) but don’t have enough data about their background (e.g. male, 24, has asthma) to derive features. Conversely, the data is right censored when you have data about a patient’s background but you don’t know their outcome.
Intervention-Tainted Outcomes
Rarely do you see a direct correlation between a patient’s symptoms and their outcome. Usually, the patient receives some treatment in between that changes what their ultimate outcome is. However, if you forget to account for the patient getting treated in your model, your model can accidentally learn the wrong lesson.
For example, let’s say that we have an extremely effective treatment for breast cancer that cures all breast cancer patients. Looking at just the diagnosis and the outcome, the machine learning model will learn that breast cancer is low risk since everyone survives. Thus, it will recommend that the patient doesn’t need any treatment. But that’s incorrect because it was the treatment that cured the patients in the first place!
Significant Missing Data
There is a ton of missing data from EHRs, which reduces the statistical power of the model and can lead to selection bias.
Measuring Success
Measuring success of a machine learning model in healthcare is also quite difficult since you have to ensure that your model will work on a long-tail of rare cases and has clinical utility. We’ll discuss how to measure success of models in a future post!
Open Source Datasets
If you want to try building some of these algorithms yourself (I would highly recommend doing this!) then you should check out these open source medical datasets:
Job Opportunities
Buoy Health (Product Manager, Software Engineer, Data Engineer, Data Scientist)
drbot.health (CTO/Tech Lead)
Enlitic (Data Engineer)
PathAI (Software Engineer, Product Manager, SWE Intern, ML Intern)
Imagen Technologies (Security Engineer, Engineering Manager, Security Engineer)
Covera Health (Director of Artificial Intelligence - Computer Vision)
What’s Next?
With this piece, we have begun digging into how ML is used in healthcare. As you can see, there is a lot of potential for machine learning to revolutionize the healthcare space and a lot of interesting challenges along the way!
In the following posts, we will delve into some more algorithms and ML subfields, such as neural networks, computer vision, and natural language processing. Stay tuned!
Was this article helpful to you? Do you have any feedback or particular topics that you want me to cover? If so, I would love to hear it! Please comment below or email me at maitreyee.joshi@gmail.com!
I really like the dog-identifying analogy!